What is a vector database and how it works
Powered by embedding models and vector embeddings, Vector databases let you search by meaning and "exact match" keywords. It is the best of both worlds.

Imagine that you're two minutes away from an important presentation.
You join the virtual meeting and confidently begin your introduction.
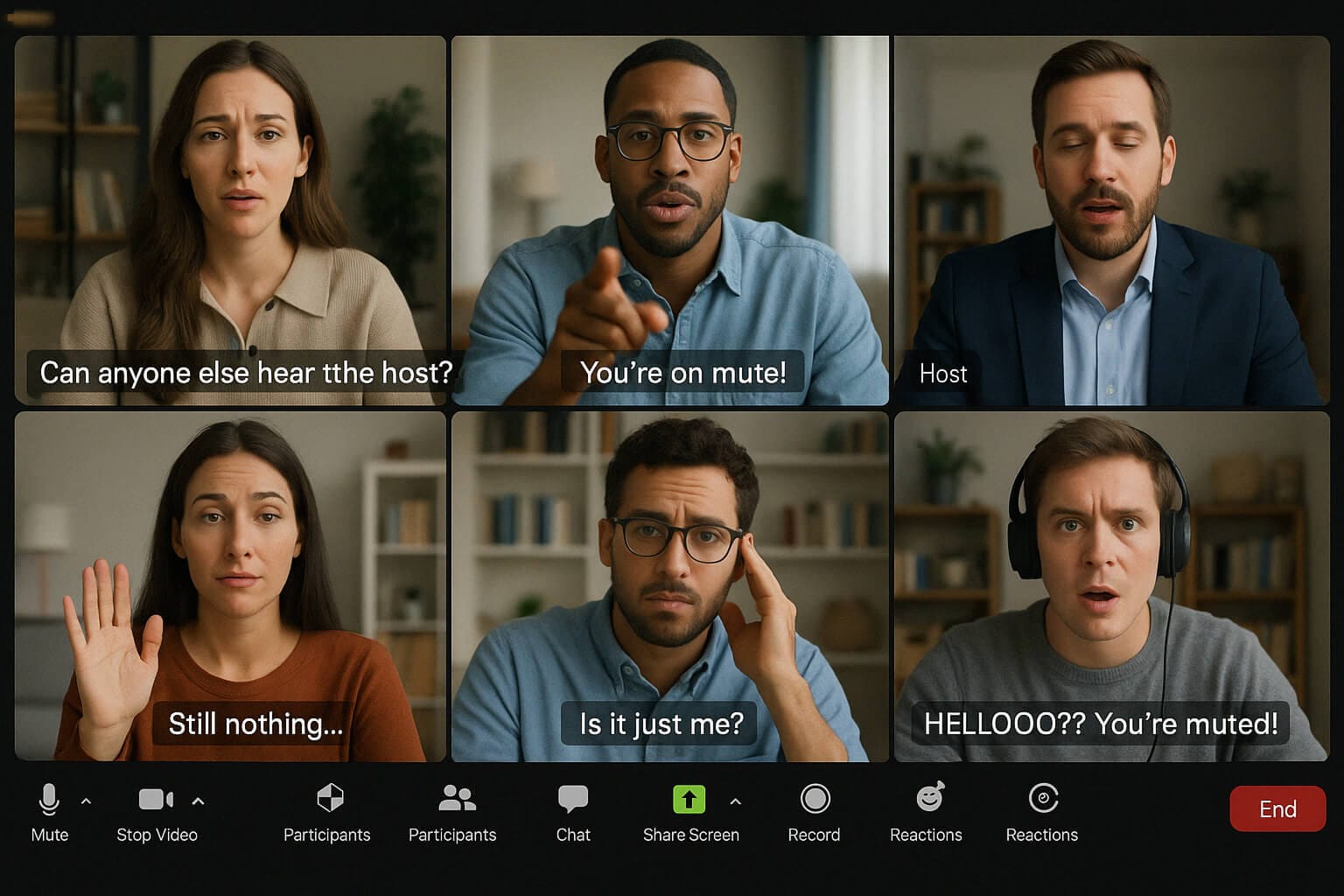
And bang!
The chat is exploding with “We can't hear you!” messages.
To fix the problem, you quickly check your settings, try plugging and unplugging your headset, but nothing works.
After all the quick trials, you search the help center asking “people can't hear me in online meeting” with hope.

What happens?
Either nothing relevant comes back, or you're thrown with dozens of generic articles about audio troubleshooting.
But the problem is, none of them address your specific urgent problem.
Why?
Because that's how traditional databases work.
The problem with traditional databases like MySQL is that they work on a simple principle called “exact matching”.
Simply put, they're like support agents who can only help if you use the exact words from their manual.
Let me elaborate...
The limitations of traditional databases
When you search for “people can't hear me in online meeting”, a traditional database scans for support articles containing those exact words.
This means, if a perfect solution exists under a different title like “Resolving microphone access and audio issues”, even though it's exactly what you need, you'll never see it.
This keyword-based “exact matching” approach creates three big problems:
- You miss relevant solutions that use different terminology
- You can't search for concepts or the underlying issues
- Support teams must manually tag the content with different keywords to catch all possible search terms
In our meeting example, traditional search fails because it doesn't understand the fact that “people can't hear me” and “microphone input configuration” are describing the same problem.
The database sees these sentences as totally unrelated because it doesn't understand their meaning.
Long story short: Traditional databases don't have the ability to understand the meaning of the data that it store.
And this is where vector databases come in.
Vector databases let you search by meaning instead of searching by keywords.
Actually, a vector database can do both:
- It can search by meaning
- It can search for exact keywords.
How powerful is that, eh?
“Yeah, very powerful. But how can a vector database understand the meaning of the content, while a traditional database can not?”
Great question!
Why a traditional database cannot understand the meaning of the data stored in it
Traditional databases store the data as is inside tables with rows and columns:
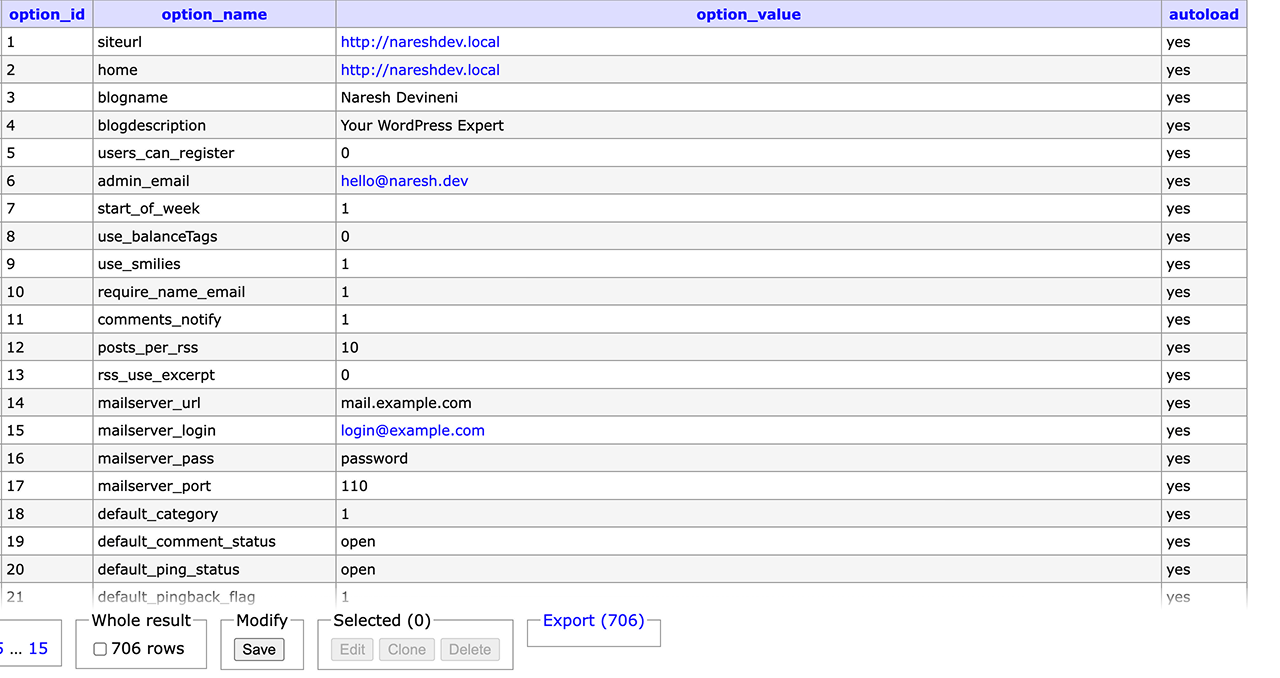
And if you notice the above screenshot, the text remains text and numbers remain numbers.
In other words, traditional databases don't transform your data into semantic representations (vectors) that capture the meaning of the data.
Instead, they store the data as is.
This is why they don't understand that “people can't hear me” and “microphone not working” are conceptually related.
They're more focused on efficient storage and retrieval based on the exact keywords or predefined patterns, but not on understanding what the content means or finding conceptually similar items regardless of the specific words used.
But on the other hand...
How can a vector database retrieve data based on their meaning?
To understand how vector databases work, we need to first understand the technology that powers them:
- Embedding models
- Vector embeddings
What is an embedding model?
An Embedding model is a specialized AI system that is trained on massive amounts of raw data to understand their meaning.
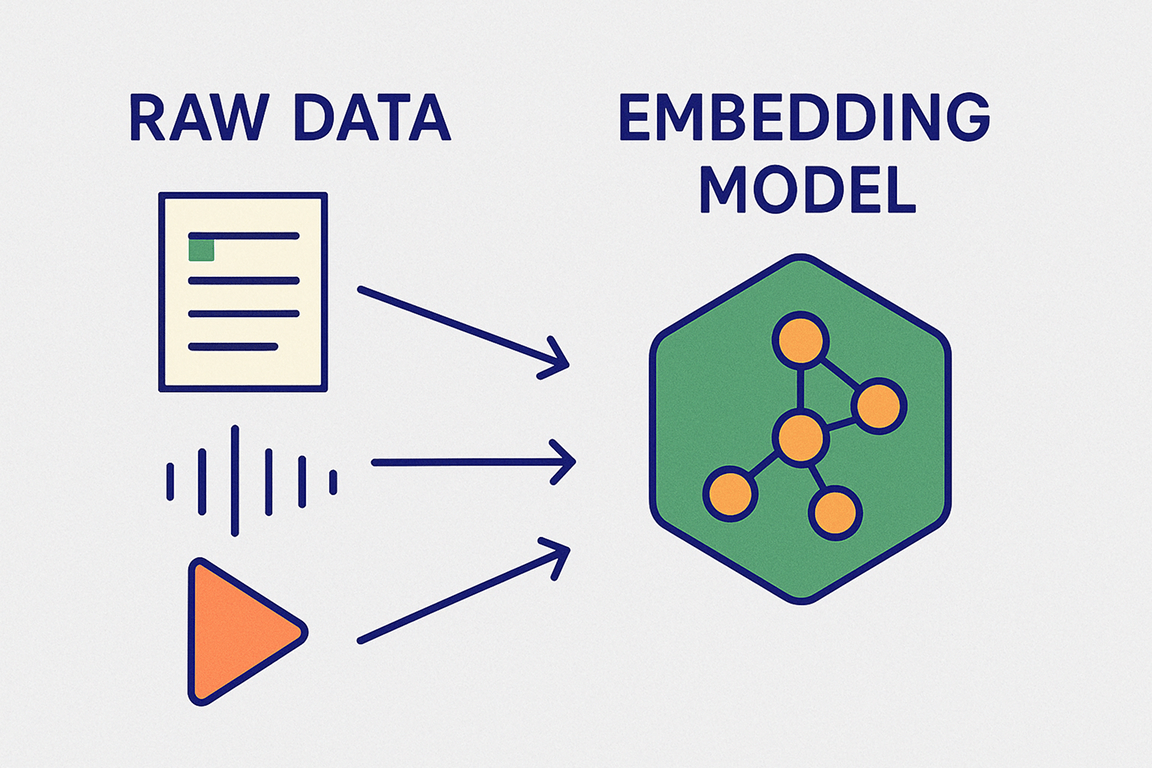
In more technical words, an embedding model is an advanced neural network trained to understand patterns in language, images, or other data.
To achieve this, an embedding model is trained with millions or billions of examples.
As a result, an embedding model can understand that words like “microphone” and “audio” are related, or that “can't hear me” is about sound problems.
And once it understands the meaning of a piece of raw data, an important purpose of embedding model is to convert that raw data into numerical representations that capture meaning:
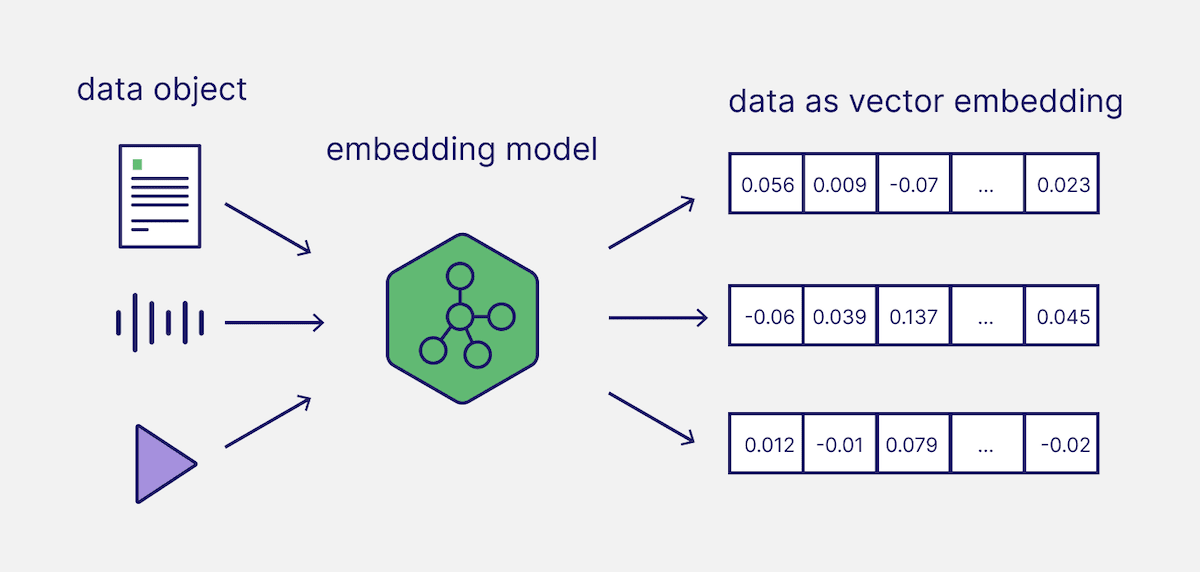
We call this numerical representations as vector embeddings.
Transforming Content into Vector Embeddings
A vector embedding is nothing but a numerical representation of a piece of data.
For example, when we run the word “Queen” through an embedding model, we might get a vector that looks like this:
[0.4246, -0.1472, 0.5509, 0.0224, -0.5665, 0.0169, 0.3210, 0.3590, 0.4095, -0.0218, 0.2191, 0.0097, 0.4469, 0.5288, 0.1690, 0.0150, 0.2874, -0.6636, -0.4674, 0.1614, -0.7712, 0.3576, 0.5123, -0.2849, -0.6076, -0.2499, -0.2459, 0.4682, 0.0838, 0.2047]
As you can see, a vector embedding is nothing but a big array of numbers.
“Woah! All those numbers to just represent the word Queen?”
Haha, yeah!
All those numbers help us capture the meaning of the word “Queen” in a detailed way.
From the terminology standpoint, each number inside a vector embedding is called as a dimension.
And each dimension of a vector embedding represents a part of the data.

For example, the dimension 0.4469 inside the above vector array represents a part of the letter “e” in the word “Queen”.
Similarly, the dimension 0.1614 inside the vector array represents a part of the letter “n” in the word “Queen”.

Although I am representing the word queen with 30+ dimensions, each piece of data is usually represented with 100s of dimensions.
This will enable the vector embedding to capture the meaning of the data in a detailed way.
And this is what helps vector databases understand the meaning of the data in an accurate way.
Also, not just words or letters, this applies to any other data type, such as:
- Images
- Video
- Documents
- Sentence of words
- Other file types
All the above file types can be converted into vector embeddings so that their meaning is captured in a detailed way.
For example, here is how an image of a dog looks like when it is converted into a vector embedding:
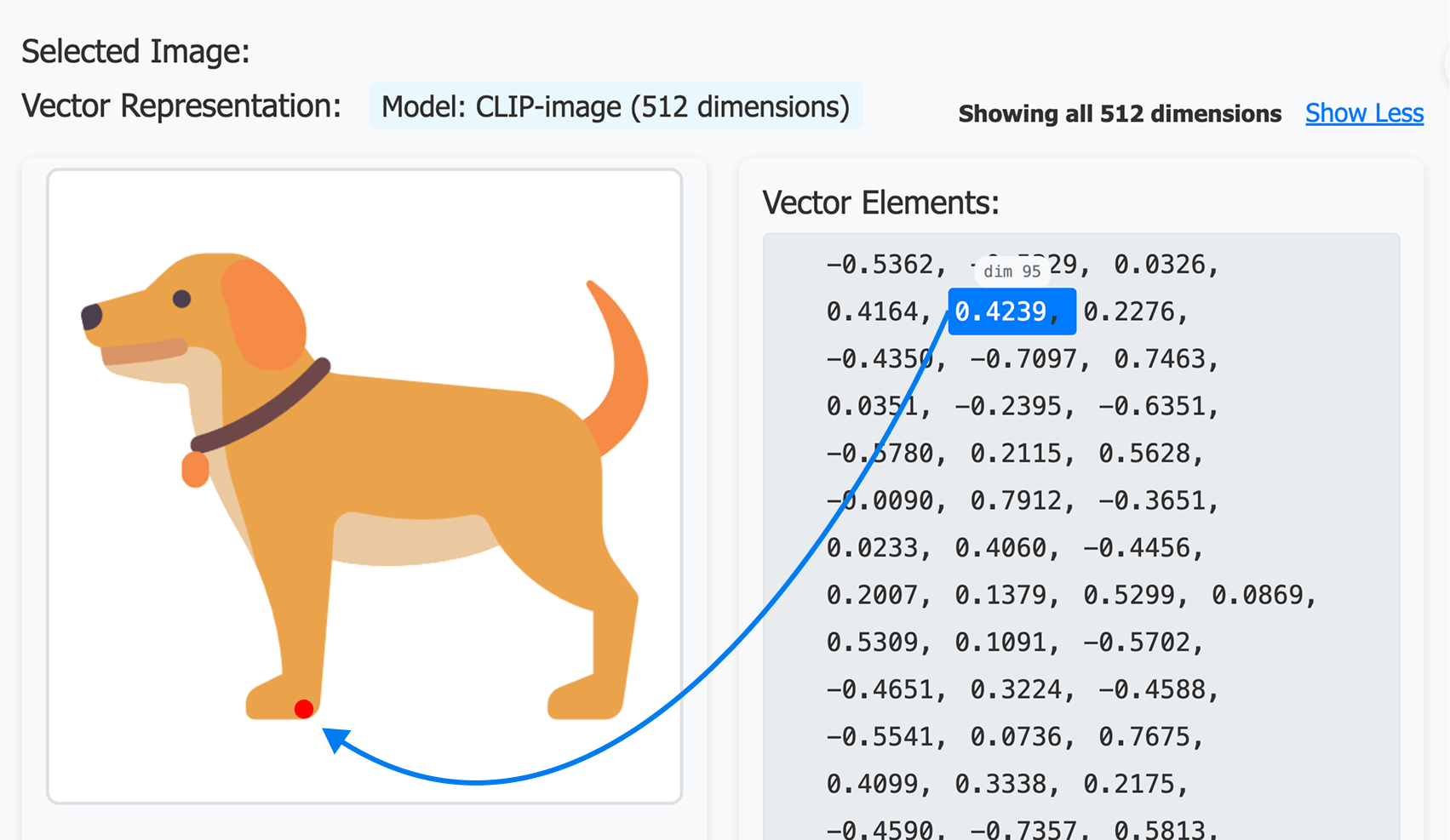
As you can see, the Dog is getting represented as an array of 512 dimensions and out of all those numbers, 0.4239 represents a part of the dog's paw.
“Oh! What tool are you using for this?”
I am glad you asked :D

The tool is called “Vector Embeddings Visualization”.
You can access the tool at https://nareshdevineni.pythonanywhere.com/.

I built this tool specifically to help you visualize how words and images look like when they get converted into vector embeddings.
The cool thing is, once you generate a vector embedding using the tool, you can click on the individual dimensions to see what they represent inside the data:
Come on, go ahead and try it out.
“Nice, but it is still a bit unclear for me. Why 512 dimensions to just capture the meaning of minimal dog image?”
Good question.
I think comparing a vector embedding to an RGB color system will help you get an answer.
Understanding Vectors Through RGB Colors
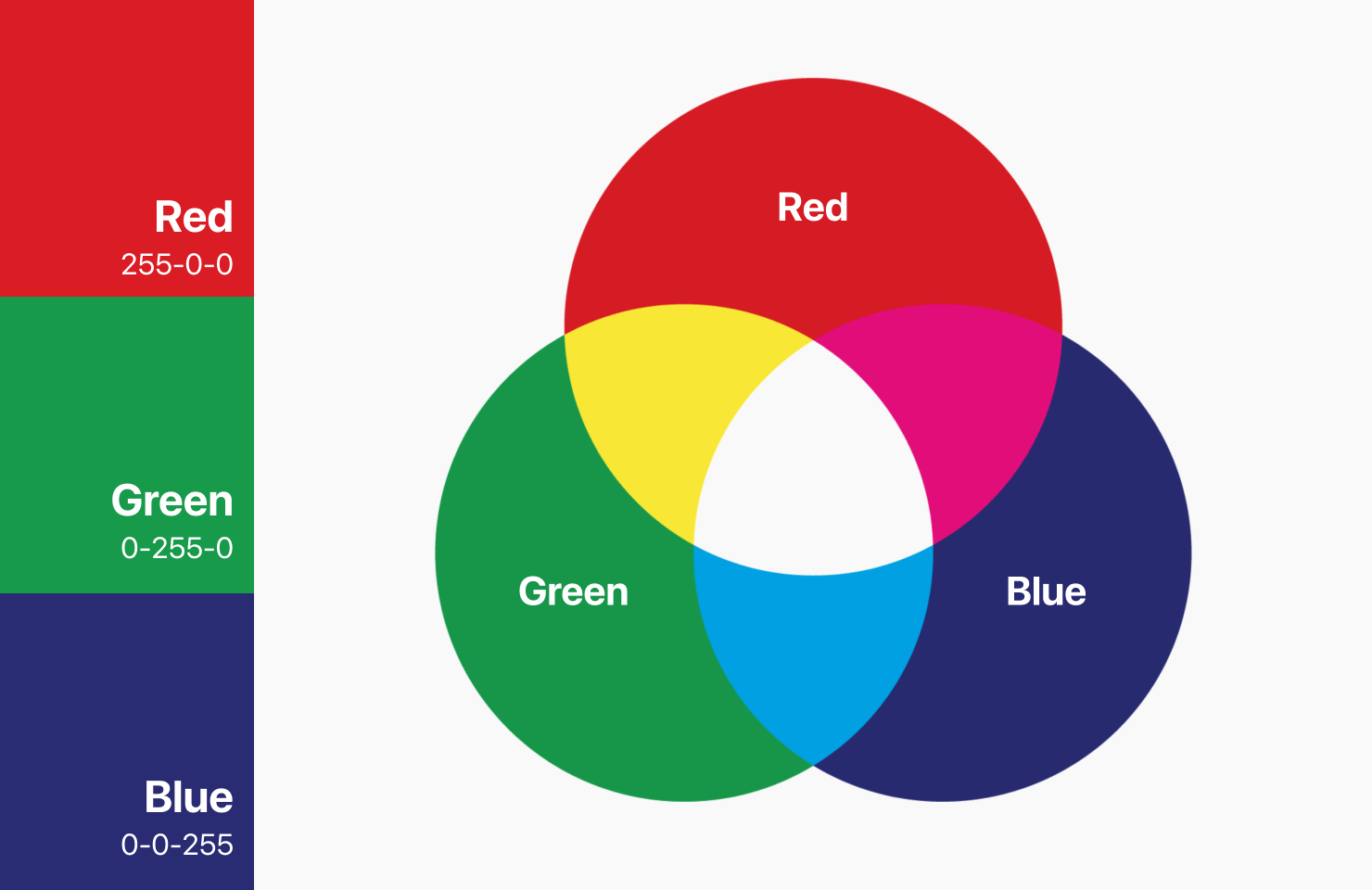
RGB stands for Red, Green, and Blue.
In RGB, every color is represented by three numbers – one each for Red, Green, and Blue.
For example:
- Pure red is [255, 0, 0]
- Royal blue is [65, 105, 225]
- Forest green is [34, 139, 34]
Each of these numbers acts like a “dial” that we can adjust to represent any color we want.
Vector embeddings work on the exact same principle, but instead of just three dimensions (RGB), they use hundreds of dimensions.
Why so many? Because to capture all the meaning in words, images, and other data, we need many more dimensions when compared to the just three dimensions we use for colors.
Each dimension in a vector is like one of those RGB dials, capturing some aspect of meaning.
When we set all these values in different combinations, we can represent very specific types of meaning.
That's the purpose of converting data into vector embeddings using as many as dimensions we need.
Vector embeddings also convey how closely two pieces of data are related
For example, when we run the text “microphone not working” through an embedding model, we might get a vector that looks like this:
[0.12, -0.33, 0.41, 0.02, 0.56, -0.19, 0.27, 0.08, ...]And for “audio not detected,” we might get:
[0.11, -0.31, 0.44, 0.01, 0.52, -0.21, 0.29, 0.07, ...]Now, notice how similar the vectors are for both the sentences.
It is these small differences in numbers reflect the subtle differences in meaning.
And in the above example, they convey that “microphone not working” and “audio not detected” are closely related.
That's the purpose of an embedding model and vector embeddings.
“Where do I get these embedding models?”
There are many embedding models in the market
For example:
- OpenAI Embeddings: Powerful text embeddings that capture nuanced meaning and are widely used for many applications
- Sentence Transformers: Open-source models specifically designed to understand sentence meaning.
- CLIP: Can create embeddings for both images and text in the same vector space, allowing you to search images with text queries
- BERT and its variants: Widely used for understanding context in language
- MiniLM: Smaller, faster models that work well for many practical applications while using fewer resources
The thing is, you can either use these pre-trained models or train your own custom embedding models for specific needs of yours.
Just remember that the better the embedding model, the better the vector database will understand what your content means.
You can try out various models by visiting the visualization tool again:
https://nareshdevineni.pythonanywhere.com/.
It randomly picks an embedding model every time you generate a new embedding.
Anyway, now that you understand the concept of vector embeddings and embedding models, let's see how a vector database utilizes them to give you meaningful search results.
How vector databases provides search results in a meaningful way
Once the vectors are generated using an embedding model, they are stored inside a vector database like Pinecone, Weaviate, or Chroma.

And the best part is, a vector database doesn't just dump the data randomly.
It organizes them carefully for fast and meaningful retrieval.
A vector database use clever algorithms to group similar vectors together.
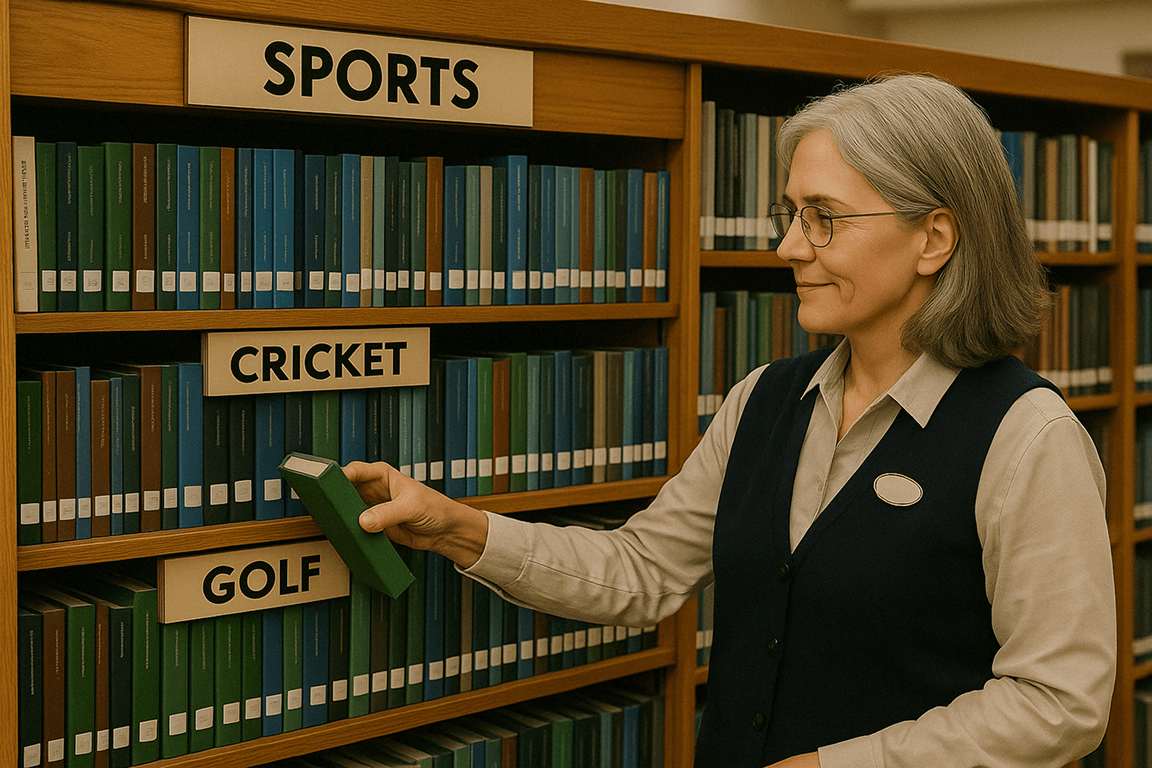
Think of it like a library organized by subject.
When you ask for a book on “How to play Golf”, the librarian doesn't check every book.
They go straight to the “Sports” section, then the “Golf” shelf.
Similarly, vector databases create “neighborhoods” of related vectors.
So when you search, they only need to check the most promising neighborhoods instead of the entire database.
For example, imagine you are maintaining a vector database of movies.
The movies are divided into three categories:
- Action
- Mystery
- Horror
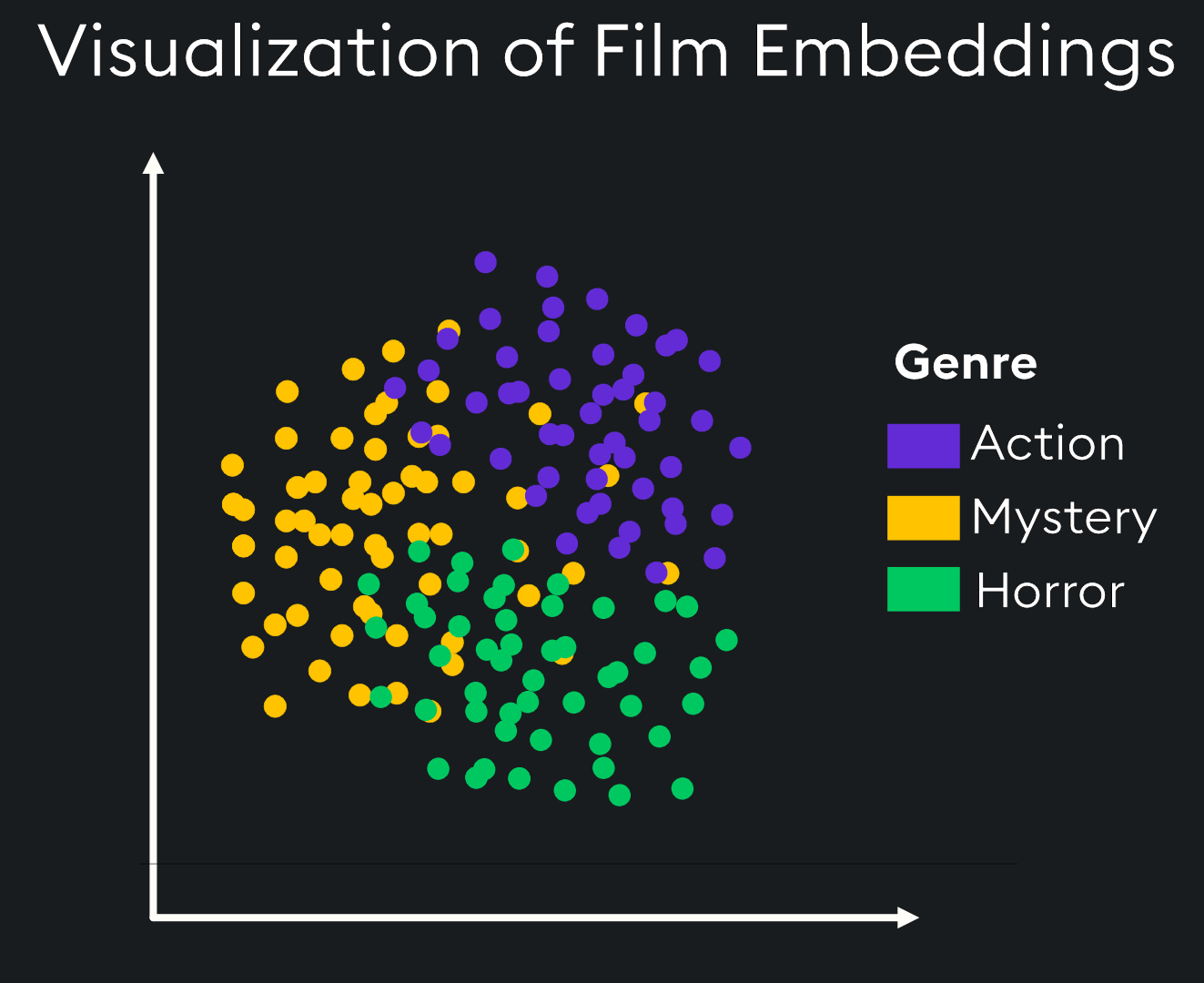
In this case, the vector database organized movie vectors into three neighborhoods based on the movie type.
All the horror movies (green) are stored in a particular location.
All the action movies (purple) are stored in a separate location.
You get the idea, right?
This way, when you search for a horror movie, it only searches the neighborhood where all horror movies are stored and will try to avoid searching the neighborhood with action or mystery movies.
Searching an entire database is a bad idea because searching through millions of vectors is time-consuming and painful.
So, vector databases avoid this at all costs by grouping similar vectors.
How meaning is organized with the help of similarity and distance
In a 3D vector space, similarity is represented by distance.
Let's use an example with animals.
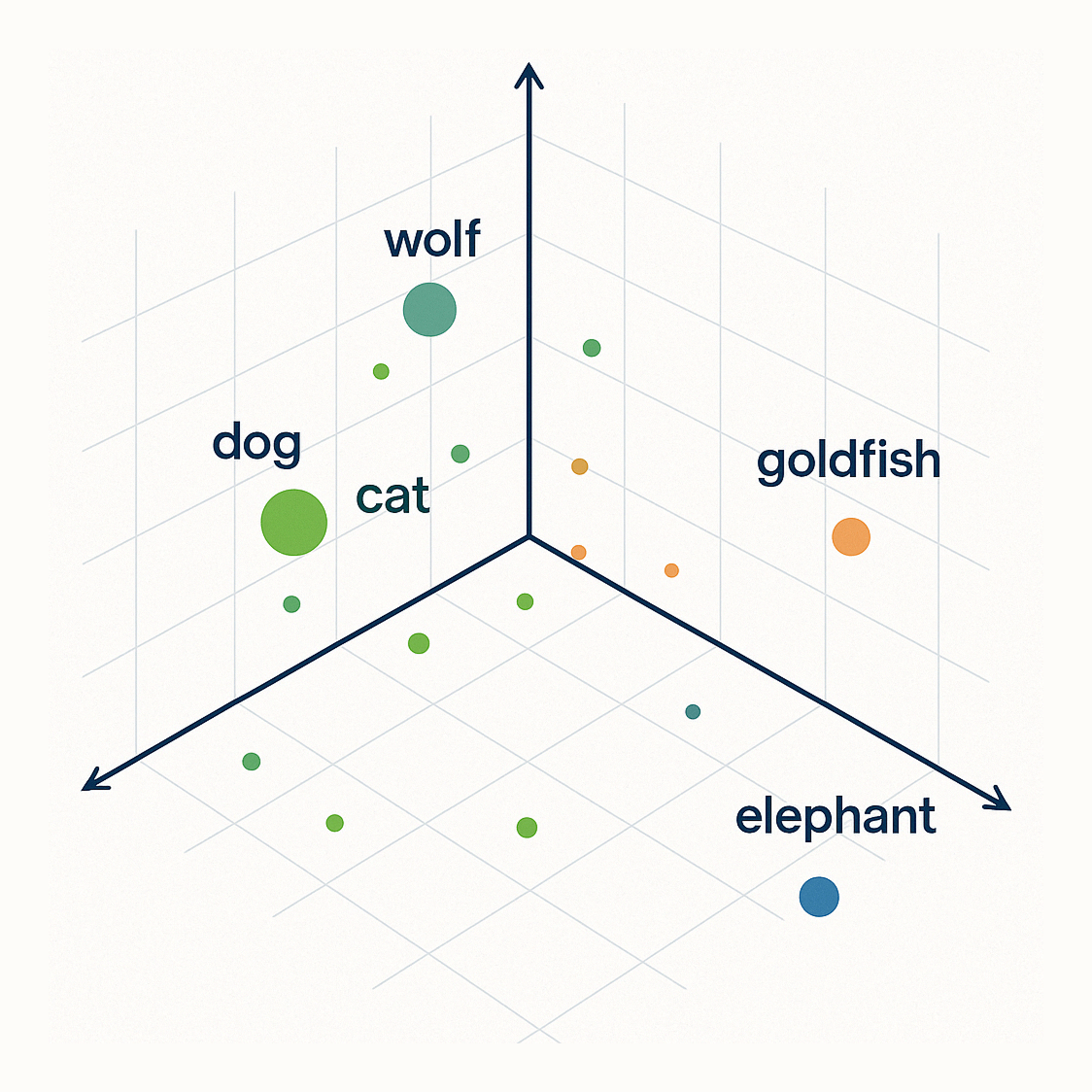
In the above 3D space representation of a vector database:
- The vector for “dog” and “cat” would be positioned close together because they're both common household pets with similar characteristics.
- The vector for “wolf” would be relatively close to “dog” because they're related canines.
- The vector for “goldfish” would be further away from the vectors of dog, cat, and the wolf. Although a goldfish is a pet, it is very different from a dog or a cat.
- Finally, the vector for “elephant” would be very far away from other vectors (completely different context)
So when someone searches for “pet that barks” in the vector database:
- Converts that query to a vector
- Finds that it's closest to the “dog” vector
- Returns content related to dogs
- May also return content about wolves (somewhat close) but not about elephants (too distant)
This organizing principle is what makes vector search so powerful when it comes to our “meeting audio troubleshooting scenario”.
Terms like “microphone not detected,” “can't hear me,” and “audio input problems” all cluster together in this space, regardless of the specific words used.
How this improve our “meeting audio troubleshooting scenario”?

When you search “people can't hear me in Zoom meeting,” the vector databases system:
- Uses AI to understand your intent, that is, fixing audio output problems
- Leverages machine learning to recognize that “can't hear me” relates to microphone issues
- Applies learned patterns to know that “Zoom meeting” means online conferencing context
- Combines all this understanding finding relevant solutions, even if they use different terminology
This AI-powered approach is why vector databases can find the right answer when you describe your problem in your own words, making technical support more accessible and effective.
Long story short: This is exactly how a vector database can retrieve data based on their meaning.
Ufff...we came a long way.
But I hope you now understand the purpose of vector databases.
Real-world use cases for vector databases
1) E-commerce sites can show products similar to what you're viewing:
2) Streaming services like Netflix can recommend similar shows and movies that you might enjoy
3) Healthcare systems can connect symptoms to potential conditions regardless of terminology
4) AI assistants use vector databases to retrieve relevant information before generating responses. For example, a website chatbot that can queries about your products and services without your intervention.
Some traditional databases now support vector embeddings and transformed into modern databases
In the past, adding vector search capabilities required maintaining a separate specialized database alongside your main database.
It used to double the complexity and create data-syncing headaches.
But today, traditional databases like MongoDB and PostgreSQL support vector search like native vector databases.
This means you can store your regular support data and vectors in the same place.
It simplifies your architecture while gaining all the benefits of meaning-based search.
Awesome, right?
Just to recap, to achieve fast, meaningful and contextual search results:
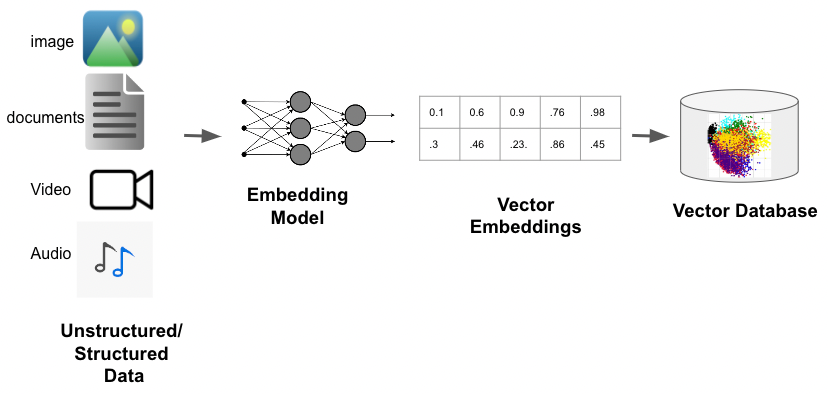
- Raw data like image, video, sentences, etc. are fed into an embedding model
- The embedding model turns raw data into meaningful vectors using numerical representation
- Finally, these vectors are stored inside a vector database and grouped based on how pieces of data relate to each other.
- This way, when you search for something using different terminology, relevant results still show up.
Anyway, now that vector databases make sense, you'll soon see how they're the backbone of smarter AI systems using RAG (Retrieval-Augmented Generation).
But that's for another day :)
For now, take some time to sleep over the concept of vector searches.
I will see you next time.



